



Pred každým používateľom počítača aspoň raz bolo potrebné získať textové informácie z obrázkov. Keď pracujete v programoch na písanie, niekedy musíte opätovne vytlačiť text, ktorý je v rastrovom alebo vektorovom obraze. Tento dlhý proces sa dá skrátiť, ak viete, ako vytiahnuť text z obrázka v programe Word.

Ak chcete konvertovať text na obrázku do dokumentu programu Word - postupujte podľa pokynov uvedených nižšie.
obsah
- 1 Cesta von
- 1.1 Pracovný poriadok
- 2 Funkcie procesu
- 2.1 Získajte výsledok
Cesta von
Zvyčajne proces rozpoznávania obrazu je časovo náročný. Bude musieť robiť hlavnú prácu ručne, ale konečný výsledok ušetrí celkový čas strávený. Je to nevyhnutné, ak existuje iba elektronický obrázok dokumentu alebo stránky knihy, z ktorej chcete text vytiahnuť.
Namiesto ručného opätovného vytlačenia informácií môžete použiť špecializované programy a služby, ktoré automatizujú túto prácu. Umožňujú rozpoznať text pomocou obrázkov z najpopulárnejších formátov, vrátane jpg, gif a png.
Pracovný poriadok
Ak sa údaje nachádzajú na vytlačenom dokumente, musíte z neho vytvoriť obrázok. Vyžaduje to skener. Je tiež potrebné, ak text na obrázku má slabé rozlíšenie alebo je rozmazaný. Do skenera by mali byť pripojené "natívne" ovládače a programy, ktoré budú prekladať všetko vo vysokej kvalite. Výsledok je ovplyvnený nielen jasnosťou písmen, ale aj ich "rovnomerným" postavením, ako aj absenciou zásahov.

Ak potrebujete získať text z nosiča papiera, budete potrebovať skener.
Ak nemáte skener, môžete to urobiť s fotoaparátom. V tomto prípade musíte správne nastaviť svetlo. Ďalší krok vyžaduje použitie špeciálnych programov, ktoré vám umožnia priamo rozpoznať text pomocou jpg. Medzi takými programami patrí ABBYY FineReader, ktorý je považovaný za lídra na trhu. Platí sa, ale jeho kvalita zodpovedá nákladom.
Funkcie procesu
Vo funkciách softvéru existuje veľa funkcií, ktoré vám umožňujú pracovať s väčšinou písma. Medzi pokročilé funkcie patrí schopnosť rozpoznať ručne písané slovo z jpg. Má mnoho výhod:
- výberu kvality.Používateľ môže zastaviť požadovanú kvalitu skenovania. Je lepšie vybrať aspoň 300 DPI, aby program ovplyvnil aj malé detaily na spracovanie a mohol pracovať s malými písmenami.
- farbu. Je potrebné, ak sú na obrázku stoly alebo iné symboly. V iných prípadoch je lepšie zvoliť čiernobiely režim, ktorý odstráni posuny farieb z písmen, čím sa stanú čistejšími. Farebný režim je vhodný pre jasné obrázky, kde je dôležité, aby sa zobrazila farba textu.
- Foto. Ak sa obrázok urobí so snímkou, program zvýši prioritu skenovania. Môžete tiež priamo fotografiu ABBYY FineReader rozpoznať v jpg. Je pravda, že to výrazne zhorší kvalitu, a preto konečný výsledok bude mať veľa chýb.
Medzi podobnými programami sú aj bezplatné služby. Medzi nimi je tiež zvýraznený Disk Google, ktorý je k dispozícii priamo v prehliadači. Práca s programom OCR Convert je strednej kvality, preto je vhodná pre tých, ktorých obraz má vysoké rozšírenie a jasné písma. Služba i2OCR ponúka podobné služby, z adresy URL sa dajú stiahnuť iba obrázky.Majú amatérsky formát, preto sa nepovažujú za profesionálne použitie.
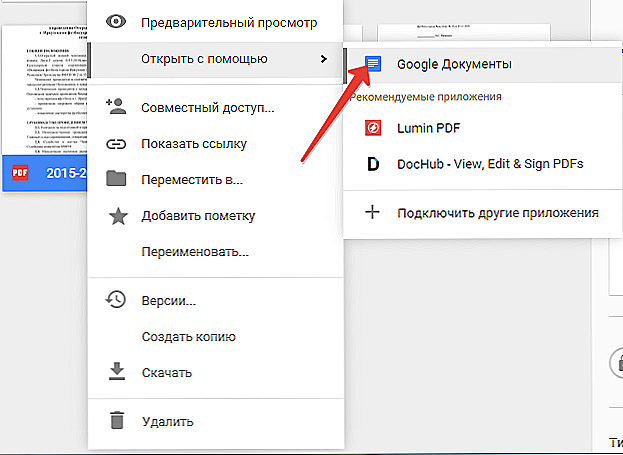
Otvorením obrázka pomocou služby Dokumenty Google dostanete dokument s už rozpoznaným textom.
Získajte výsledok
Po spustení skenovania zvyčajne trvá niekoľko minút, kým sa dosiahne výsledok. Tento indikátor závisí od zložitosti a množstva dostupného textu. Po spustení práce budú programy v automatickom režime prideľovať oblasti na testovanie a konvertovať ich. Po ukončení procesu môžete znovu rozpoznať jpg dáta alebo zaostriť na určité časti dokumentu.
Dokončený výsledok sa exportuje do súboru programu Word. Výsledný text je možné upravovať pri pozorovaní chýb alebo pokračovať v ďalšej práci. Rozpoznanie textu s obrázkami jpg nie je ťažké, ak správne pripravíte obrázok. Tento proces môže ušetriť veľa času, na rozdiel od manuálneho opätovného vytlačenia informácií.
Keďže práca s rozpoznávaním textu z obrázka vyžaduje zdrojový kód vysokej kvality, musíte najprv nájsť obrázok s vysokým rozlíšením. Tým sa zrýchľuje samotný proces spracovania údajov a zároveň sa zníži celkové množstvo chýb.
![Ako zobraziť obrázok z prenosného počítača, smartfónu alebo tabletu do televízie cez Wi-Fi? TV ako bezdrôtový monitor [Intel WiDi a Miracast]](http://ateasyday.com/img/images/kak-vivesti-izobrazhenie-s-noutbuka-smartfona-ili-plansheta-na-televizor-po-wi-fi-televizor-kak-besprovod.gif)







{kind=link}